
Table of Contents:¶
- Introduction
- Resources
- Data Scraping
- Exploratory Data Analysis
- Creating a Prediction Model
- Conclusion
1. Introduction¶
Video games have been a popular form of entertainment for decades, with the first recorded game dating back to around 1958. However, they would not become popularized until the rise of arcades and arcade games around the 1970's. Over the years video games have evolved and now come in a variety of different forms and genres. Many people argue about what the 'best' genre is, and the 'best' game of all time is. This all comes down to personal preference, but there are common themes and patterns in all of the most popular games. This dataset contains information dating back to as far as 1985 and lists over 16,500 games. Notable descriptors are the platform, year released, genre, sales, critic scores and rating. Analyzing the most popular games using these descriptors, we can create a model to predict what makes a popular and successful game.
Why would we want to know this?¶
In learning and creating an accurate data model, we would be able to create and set all the attributes for creating the best video games. It also ensures that no developers would waste time and effort into making a game that was doomed to fail from the start.
What makes a video game popular?¶
While something like popularity is subjective and the most popular game of all time will change with whoever you ask. There are a few statistics and attributes we can use to standardize this. We will be using global sales, as well as scores given out by the critic and the user. Doing this we can estimate and judge which games are 'popular' all on the same standard.
2. Resources:¶
- Video Game Dataset provided in this project linked here:
- Pandas
- Numpy
- Matplotlib
- Scikit-Learn
3. Data Scraping¶
To start off, we want to simply import all of the libraries before we begin. After that step, we're using pandas to read the csv (comma separated value) file and convert it into a pandas dataframe that we can refer to throughout this project. The data was scraped from vgchartz.com and can be found here
About the Data¶
Data Content¶
The data contains information about several different aspects of the video games. These include:
- Rank
- Name
- Platform
- Year of Release
- Genre
- Publisher
- North America Sales, European Sales, Japan Sales, All other sales, Global combined Sales (All in per Million Sold)
- A critic Scores, with the number of critcs whom reviewed it; and user scores, with the number of users whom reviewed it.
- The developer and the ESRB Rating (More information about the rating and how they are rated can be found here
Data Size¶
There are a total of 16179 total different video games with recorded data that we will be analyzing. For some of the older and less relevant games there will be NaN for some attributes. We will be keeping these as NaN for now as to not skew the data in a direction, and will only remove them as needed.
We will be outputting the pandas dataframe to help understand what exactly the data is and how it looks like. The table is sorted by global sales, with the highest global sales at the top (Wii Sports), and the lowest at the bottom
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
df = pd.read_csv('vgsales.csv',sep=',')
df
4. Exploratory Data Analysis¶
How have sales of video games performed over time?¶
Historically we want to analyze how video games as a whole has changed in popularity throughout the years, plotting the total global sales per year will give us an accurate representation of this relationship. We will as well be plotting the number of video games released per year to show and discuss a relationship between the two.
#Finding the unique years
years = df.Year_of_Release.unique()
sales_per_year = []
listings = []
for year in years:
if year == np.nan:
years.remove(year)
#Have to sort the years in ascending order to ensure
#the correct order for global sales per year
years.sort()
#Adding the sum of global sales from each year to the sales_per_year array
for year in years:
rows = df.loc[df['Year_of_Release'] == year]
listings.append(len(rows))
sales_per_year.append((rows['Global_Sales']).sum())
plt.plot(years, sales_per_year,color='blue',label='Global Sales (in millions)')
plt.plot(years, listings,color='red',label='Number of Listings (in millions)')
plt.xlabel('Years')
plt.title('Number of Games Released vs. Total Global Sales')
plt.legend()
plt.show()

After plotting the total global sales vs. years, we can see that there is a steep increase in sales until its peak it 2008. However, this can be due to the fact that there is a large bulk of sales until 2010 and a drop off in listings that would explain the "decrease" in sales post 2010.
Looking at different attributes¶
Another interesting way we can analyze the data is by viewing correlation of sales compared to different attributes of these video games. The ones we will want to analyze are the genre of a game, which can vary drastically from family friendly platformers to shooter games. The second one we'll be comparing is how regions correlate with global sales by looking at games' sales in NA, EU, JP, Other.
Group by Genre¶
Genres = df.Genre.unique()
print(Genres)
There is a total of 12 different categories that this dataset classifies video games as. However, usually games are more than one genre at a given time, we are using the main genre identifier.
There are: Sports, Platform, Racing, Role-playing, Puzzle, Shooter, Simulation, Action, Fighting, Adventure, Stategy, and Misc
Genre_Totals = []
for genre in df['Genre'].unique():
Genre_Totals.append(int(df.loc[df['Genre'] == genre]['Global_Sales'].sum()))
fig = plt.figure()
ax = fig.add_axes([0,0,1.75,1])
ax.bar(Genres[0:-1],Genre_Totals[0:-1])
plt.title('Total Global Sales Per Genre (in millions)')
plt.xlabel('Genre')
plt.ylabel('Total Global Sales')
plt.show()

# To Create a Pie Chart
genres = df.Genre.unique()
# Num will represent the total amount of games in the genre
num = []
# Removing the NaN Genre
genres = genres[:-1]
#Iterating through all genres and finding games that have the same genre in the dataframe
for g in genres:
num.append(len(df.loc[df['Genre'] == g]))
sizes = num
fig1, ax1 = plt.subplots()
ax1.pie(sizes, labels=genres, autopct='%1.1f%%', startangle=90,pctdistance=0.8)
ax1.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.
plt.title('Frequency of Games per Genre')
plt.show()

As we can see with these results from the first bar plot, sports and action games are the top two genres with the highest global sales by a staggering amount. When we look at the pie chart, we find that there are in general more games listed under Action and Sports in this dataset making up 14% and 20.2% respectively. There is as well significantly less games for the two lowest selling genres: strategy with 4.1% and Puzzle with 3.5%. Keep in mind that this pie chart disregards data with a missing genre.
Group by Region¶
When analyzing this dataset, we have to take into account the regional differences and how this affects sales. Do video games do well in different regions of the world? Here, we plan to plot exactly how much of a difference there is between regions NA,EU,JP and Other parts of the country using a bar plot.
Regions = ['NA', 'EU', 'JP', 'Other']
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
ax.bar(Regions,[df['NA_Sales'].sum(),df['EU_Sales'].sum(),df['JP_Sales'].sum(),df['Other_Sales'].sum()],
color = ['red', 'orange', 'green', 'blue'])
plt.title('Total Copies Sold Per Region (in millions)')
plt.xlabel('Region')
plt.ylabel('Total Game Copy Sales')
plt.show()

It's clear looking at this bar plot that there are almost twice as many games sold in the NA region as opposed to the EU, JP or other regions. This could be due to different factors such as population but is still a significant point of data.
Which platform is the most profitable?¶
We can take a simplistic approach to answer this question by comparing total global sales of each platform with the number of games listed in each platform. The visualization will show just how many games are directly contributing to sales globally. Using a grouped bar plot to pair the two comparisons is an efficient method of showing the data in a concise and informative manner. We can use also use matplotlib and add an argument to account for the width of the bar to fit two bar plots.
platforms = df.Platform.unique()
total_sales = []
num_of_games = []
# Adding the total sales from every game in each platform and also tracking how many
# games were released in total for each plotform.
for p in platforms:
total_sales.append(int(df.loc[df['Platform'] == p]['Global_Sales'].sum()))
num_of_games.append(len((df.loc[df['Platform'] == p])))
# Need to set the bar width to an arbitrary value in order to have optimal spacing
bar_width = 0.35
x = np.arange(len(platforms))
fig, ax = plt.subplots(figsize=(18, 8))
# Creating grouped bar plots, offsetting the second one with the bar width
bar1 = ax.bar(x,total_sales,width=bar_width,label='Total Copies Sold (in millions)',tick_label=platforms)
bar2 = ax.bar(x+bar_width,num_of_games,width=bar_width,label='Number of Games Released')
plt.title('Market Share per Platform')
plt.legend(prop={'size':12})
plt.xlabel('Platform')
plt.show()

The chart above shows that the PS2 has sold the most total copies in millions, with the xbox360 lagging behind by about 300 million. One thing to keep in mind when looking at this graph is that the number of games released is in single digits, while the copies sold is in millions. The PS2 has been out for the longest period of time, with an initial release of March 4, 2000; explaining why it has both the most amount of total copies sold and the number of games released.
5. Creating a Prediction Model¶
df.dropna()
df.head(5)
Data for the Global Sales Prediction Model¶
For this prediction model, I am using the Critic Score data and User Score data to see if they have any influence in the total number of sales globally. I am using libraries from SKLearn to create the models and also score the results.
We will be using the SVC (Support Vector Classifier) to feed data and attempt to predict and classify the data without knowing the answer. SVC fits the data and provides the best fit hyperplane that divides or categorizes the data, which we then use to predict information. You can take a closer look at this and see another example here 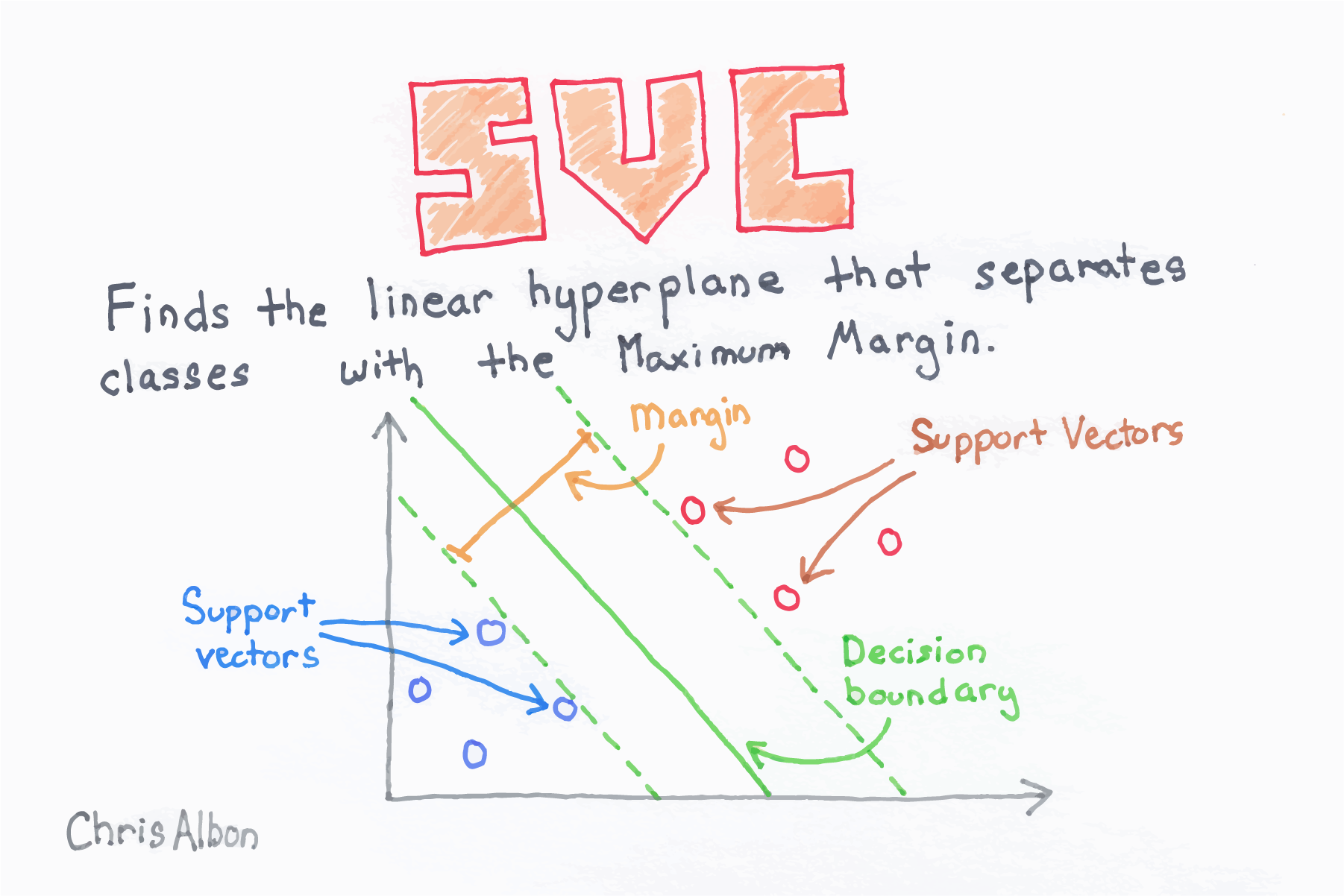
#Prediction model libraries that I am going to use for the analysis
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
#create a list of total sales per year
#allows us to standardize the sales values in the next step
total_sales = {}
for x in df['Year_of_Release'].unique():
total_sales[x] = df.loc[df['Year_of_Release'] == x]['Global_Sales'].sum()
print(total_sales)
#creating a new dataframe to create a standardized number of scores
sales = df[['Year_of_Release','Genre', 'Critic_Score', 'Critic_Count', 'User_Score','User_Count','Global_Sales']].copy()
sales = sales.dropna()
for x in sales.index:
sales.loc[x,'ave'] = total_sales[sales.loc[x,'Year_of_Release']]
#creating a new column that creates a standardized value for the score
#the standardized value is the percentage of sales that contributes to the total
sales['stand'] = sales['Global_Sales']/sales['ave']
In order to use the global sales numbers in my prediction model, I need to create data that can be useful for my model. I am creating a new data value in the dataset that shows the standardized global sales. It is important to create a standardized score because the number of total sales increased as the year increased. If I am going to use Critic Score data and User Score data as the main predictors, I need to be able to compare the sales data of the years together. Creating this standardized global sales percentage gives me the percentage of sales based on the total for that year which allows me to compare the different years easier. Although it is not an exact number of sales, it gives a percentage of how many sales that game would have of the total number of sales for that year.
#Filling in the missing values for the user score by inserting the average
#Also converts the user scores from strings into floats so that they can be used as a feature
mean = 0
i = sales.loc[sales['User_Score'] < 'A'].copy()
for x in i.index:
mean += float(sales.loc[x]['User_Score'])
mean = mean/len(sales)
for x in sales.index:
if sales.loc[x]['User_Score'] > 'A':
sales.loc[x,'User_Score'] = mean
else:
sales.loc[x,'User_Score'] = float(sales.loc[x]['User_Score'])
sales.head(5)
Some of the User Scores are missing due to various unknown reasons. Instead of just dropping these data values, I have decided to hot encode the average score into the data. In addition to this, I need to convert the data from the original dataframe into floats from strings so that it is usuable in the model.
# 2020 contains an outlier that should not be included in the data
# There is only a single data point from 2020 and it is not accurate when applied to the data
sales = sales.loc[sales['Year_of_Release'] < 2019]
# There are a large amount of values that do not have a critic or user score.
# Since this is an important factor in predicting global sales, I have chosen to drop the empty data values.
sales = sales.loc[sales['Critic_Score'] > 0]
# Selecting large middle portion of dataset that fits majority
# (Wii Sports is a huge outlier -> Best sold game of all time)
# Avoids the outliers that will skew the model
q1 = sales['Global_Sales'].describe()['25%']
q3 = sales['Global_Sales'].describe()['75%']
iqr = q3 - q1
sales = sales.loc[(sales['Global_Sales'] > (q1)) & (sales['Global_Sales'] < (q3))]
q1 = sales['User_Count'].describe()['25%']
q3 = sales['User_Count'].describe()['75%']
iqr = q3 - q1
sales = sales.loc[(sales['User_Count'] > (q1 - iqr)) & (sales['User_Count'] < (q3 + iqr))]
When viewing the dataset, there are some points that are outliers from the overall trend of the data. Including these points in the dataset would decrease the accuracy of the majority of points so I have decided to remove them. These games are the extremely popular for possible outside factors like Wii Sports.
# Creating the sales groupings based on the dataset
for x in sales.index:
val = sales.loc[x,'stand']
if val <= 0.00018:
sales.loc[x,'sales_group'] = 0
elif val > 0.00018 and val <= 0.0004:
sales.loc[x,'sales_group'] = 1
elif val > 0.0004 and val <= 0.0008:
sales.loc[x,'sales_group'] = 2
elif val > 0.0008 and val <= 0.0019:
sales.loc[x,'sales_group'] = 3
elif val > 0.0019:
sales.loc[x,'sales_group'] = 4
print('0:',len(sales.loc[sales['sales_group'] == 0]))
print('1:',len(sales.loc[sales['sales_group'] == 1]))
print('2:',len(sales.loc[sales['sales_group'] == 2]))
print('3:',len(sales.loc[sales['sales_group'] == 3]))
print('4:',len(sales.loc[sales['sales_group'] == 4]))
# Encodes the genre (Categories) into a numerical representation so it can be used in the model
encoded_genres = {}
counter = 0
for genre in df['Genre'].unique():
encoded_genres[genre] = counter
counter += 1
print(encoded_genres)
# Replacing the genres with the new encoded genres
sales.replace(encoded_genres, inplace=True)
sales = sales.dropna()
print(len(sales))
sales.head(5)
# Creates a plot that shows the correlation between Critic and User Review Scores
# Typically, better Critic score means better User score
plt.scatter(sales['Critic_Score'], sales['User_Score'], c=sales['Global_Sales'], alpha=.1)
plt.title('Correlation Between Critic and User Scores')
plt.xlabel('Critic Score')
plt.ylabel('User Score')
plt.show()

When looking at the Critic and User Score plot, it becomes clear that there is a trend that the scores are similar. When the Critic score approaches values around 70-80, the User score is generally around 7-8. This may have some influence on the total number of sales globally. The model that I am creating is to test this theory.
# Splits the dataset into features (Critic and User info) and target (sales grouping)
# Splits these two groupings into training and testing datasets
X_data = sales[['Critic_Score', 'Critic_Count', 'User_Score', 'User_Count']]
Y_data = sales['sales_group']
X_train, X_test, y_train, y_test = train_test_split(X_data, Y_data, test_size=0.30)
# Uses SVC classification from SKLearn to create a model for predicting the sales group
clf = SVC(kernel = 'linear', C = 1.0)
clf.fit(X_train, y_train)
# Shows the accuracy of the prediction model
print("Training Data Score:",clf.score(X_test,y_test))
The model is not very good at predicting the relative global sales based on the Critic info and User info. This can be explained by some other factors. Wii Sports has the most sales globally because it was included with the Wii. There are other factors that contribute to how well a game sells that are not included in this dataset. Critic Score and User Score are generally better on higher grossing games but it is difficult to predict how many units will sell by those means alone.
Data for the Rating Prediction Model¶
For this prediction model, I am doing something to the first one however this time I am trying to predict the game's rating based on the Genre and Critic/User Scores. The process to create the models is similar to that in the previous.
# Encodes the genre names into numbers so that they can be used as a feature
encoded_genres = {}
counter = 0
for genre in df['Genre'].unique():
encoded_genres[genre] = counter
counter += 1
print(encoded_genres)
# Encodes the ratings types into numbers so that they can be used as a feature
encoded_ratings = {}
counter = 0
for x in df['Rating'].unique():
encoded_ratings[x] = counter
counter += 1
print(encoded_ratings)
# Creates a dataset for the values we want to use as the features in our prediction model
data = df[['Genre', 'Critic_Score', 'User_Score', 'Rating']].copy()
# Replaces the genre names with the encoded value
data.replace(encoded_genres, inplace=True)
# Replaces the rating types with the encoded value
data.replace(encoded_ratings, inplace=True)
data.replace('tbd', 0, inplace=True)
data = data.dropna()
X_data = data[['Genre', 'Critic_Score', 'User_Score']]
Y_data = data['Rating']
X_train, X_test, y_train, y_test = train_test_split(X_data, Y_data, test_size=0.30)
clf = SVC(kernel = 'linear', C = 1.0)
clf.fit(X_train, y_train)
print(clf.score(X_test,y_test))
This model is much more accurate than the previous and can actually give us some insight on what the rating is more likely going to be. From the multiple tests that I have run on the dataset (getting training and testing data samples from the larger dataset) my results have been ~70% everytime. This gives us much more confidence and could potentially be used on new data values to give a semi-confident prediction.
7.Conclusion¶
Video Game popularity is something that is very difficult to predict. The market is always dynamic, changing depending on whatever game is blown up and popular at the time. There could be a game which everyone is talking about one day, and the next it could be forgotten as another game has recieved popularity and hype. The biggest example of this recently is the accelerated climax and subsequent downfall of the game known as 'Fall Guys'. Fall Guys blew up recently, with everyone within the gaming atmosphere talking about it and playing it. However, Fall Guys left as quickly as it came when the new hit game 'Among Us' blew up even bigger, with everyone around the world playing it (You can read more about it here and here). It is difficult to guess which game will be popular and for how long, even with the amount of data available.
Analysis¶
The model for the Popularity AKA the global sales of the video games we used the User reviews and counts of review, as well as the critic reviews and counts. However, using this data we find that the training data score is only ~.4, whereas we normally want around a score of .80. This means that while these are a subtle predictor for it, there are multiple other values and attributes that will count towards popularity.
Although when we incorporate the genre for the model in the second model, without looking at the user and critic counts, the model accuracy improved drastically. The model improves to around ~.70 - hence when we look at the critic and user review level and combine it with the genre we attain a semi-accurate predictor. But, this is still not the ideal level for the model. There are multiple other predictors that affect the global sales and the popularity of video games
Possible Causes¶
There are many different attributes in the unstable market of video games. A large portion of popularity would come from marketing the game and how effecient their team is. Usually the big game programming companies always sell a lot of units no matter what game it is, because they are able to afford pushing the game everywhere to everyone. Another attribute would be social media and hype around the game. A lot of games come into popularity by twitch streamers, where many individuals see their favorite creators play games. You can read more about this phenomenon from the article 'The impacts of live streaming and Twitch.tv on the video game industry'.